
The second project we did at Metis focused on scraping our own data from the web and fitting a model to perform a regression.
For our second project (which Metis calls “Project Luther”), we were given the option to analyze movie data, sports data, or wine data. Since my total lack of understanding of sports and wine might be a complete detriment when it comes to figuring out what factors and features are important for my model, I decided to stick with good ole movies.
My project goal: Predict the IMDB rating of the sequel movie in a franchise
I thought it would be interesting to see if we could predict how well a sequel was rated given how well the original movie did and some other factors about the production of the sequel movie. Note that I only considered Movie 1 and Movie 2 of a franchise (e.g. for Harry Potter, I only looked at Sorcerer’s Stone and Chamber of Secrets). This is largely because there might be a different relationship between Movie 1 and Movie 2 than Movie 2 and Movie 3 and etc. By looking at the the first two movies of a franchise, all my movies will be on the same playing field.
I needed to pick some features that will help my model define what makes a poorly rated sequel movie different from a well rated sequel movie. The features that I wanted to use in my models are:
Just as a note, out of all of these features, the original IMDB rating had the highest correlation with the sequel IMDB rating. Take a look at these two variables plotted against each other below, with the dotted line representing perfect correlation (i.e. if the original IMDB rating = sequel IMDB rating): 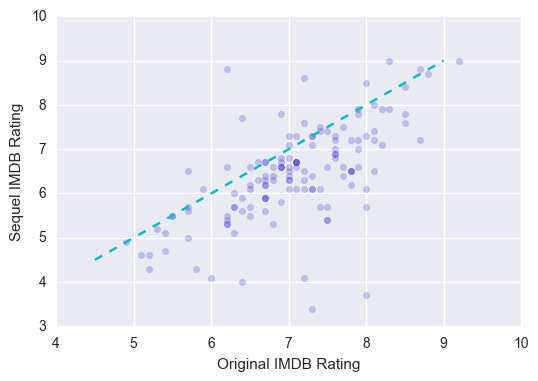
Now that I know what features I want to use, I have to get that information from websites. Pulling information and data from websites is also known as “scraping.” I had two awesome tools on hand to help me scrape websites, one is Beautiful Soup and the other is Selenium. Websites are all written in HTML which has a very well defined manner of encoding the information that is displayed on the website to people like me and you. To take a look at the HTML for any website, just right-click and hit “inspect.”
Most of the content on websites are labeled by HTML tags, that tell you what kind of information is contained in that piece of HTML. Some examples of tags are “heading”, “table”, and “paragraph.” The way that scraping works is that you find a way to uniquely locate the information you are trying to pull from the website (by using the HTML tag or other tricks) and then write a program with the help of Beautiful Soup or Selenium to isolate it and turn it into a readable, organized format. Then you can apply that to a hundred other links that are set-up just like it to be able to pull tons of data from many pages at a time.
So for my project, I scraped a table of movie franchises from boxofficemojo.com and then fed those movies into IMDB and scraped the separate movie pages to get all the information I needed. Beautiful Soup is a tool that I used to pull the raw HTML of the website and parse through the tags that I need. It’s extremely fast and really efficient, but sometimes can be detected as a bot by websites with security measures which can lead to your IP address being blocked! Selenium on the other hand is a different tool that actually opens up a browser on your computer and simulates a real user, clicking different links, to navigate to the pages you need. I used it to individually search IMDB for every movie title I had scraped from the table. Since Selenium is actually clicking through links on a browser, it can never be detected as a bot, but it also can be really slow compared to BeautifulSoup.
After all my scraping, I only had 135 movie franchises to work with, which is considered to be quite a small data set. I had to I ran all the models we learned in class on them which include linear regression, lasso, random forest, and gradient boosting. I won’t get into the details of what all these models are, but encourage people to learn more about them if they’re interested! Because my data set was small, I had to train and test my models on all the same data, but incorporated a method called cross-validation to help with possible over-fitting from my models (since predicting on the same set that the model learned from would be similar to asking someone to regurgitate something they’ve memorized, as opposed to extrapolating a conclusion based on past knowledge). To cut to the chase, my best model (meaning it had the lowest measure of error) ended up being gradient boosting. The results are shown below, with the dotted line representing perfect predictions.

These results were fairly decent (at least some improvement on just the raw plot of original ratings v sequel ratings), but we see that the model had some issues with accurately predicting sequel ratings that ended up having really low or really high IMDB ratings.
I thought the model had these large prediction inaccuracies largely because my dataset was too small. So I went searching online for a more comprehensive list of franchises. Fortunately, I found one here at the-numbers site. I processed this data identically to the way I processed the information from boxofficemojo site. I scraped their table and then funneled it into IMDB to get the relevant information. From here, I was able to almost double my dataset to get 306 movie franchises.
I ran the same models and found again that gradient boosting gave me the least measure of error. Now that I had more data, instead of using cross-validation, I used a train-test split, which means I trained my model on a portion of my data and then could test it on a different portion that the model hasn’t ever seen before to measure how well it did. The results are plotted out below, with the dotted align again representing theoretical perfect predictions:
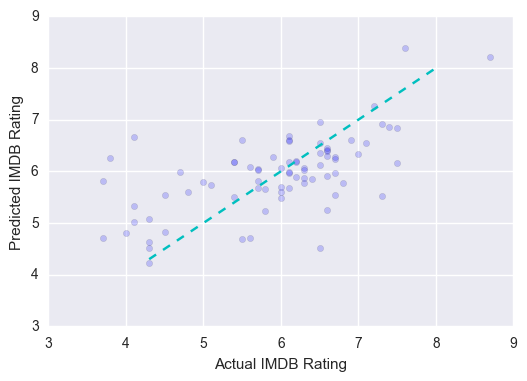
The model ended up having a r^2 of about 0.39 which isn’t fantastic, but still better than anything else I had come up with so far. It was still having some trouble accurately predicting low scoring sequel movies, but looking at the distribution of the sequel movie IMDB ratings it became somewhat apparent:
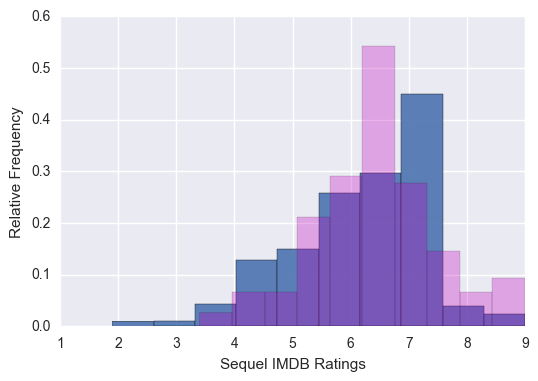
We see that there are very few examples of low sequel IMDB ratings in the first place. We can’t really expect a model to “know” what a low rated sequel movie would look like if it has only ever “seen” 3 or 4 examples. A very good lesson to learn.
The conclusion of a lot of people’s projects this time was something along the lines of “the model didn’t perform that well.” And although it probably felt kind of depressing for everyone, it brings to light a very important point about this chaotic universe we are trying to make sense of: the world is noisy. Sometimes the thing you are trying to predict has a really high signal-to-noise ratio and it’s really hard to pick out the signal with the features or variables you are trying to use. Not everything is clear cut and data science isn’t about just applying models to every problem that arises, but understanding which problems have a chance of being accurately modeled. I think that is a skill that will require a ton of experience to develop, but one that is crucial for ultimately being successful in the field.
Thanks for reading and if you want more information on my project and some of the details of how each of the models did, check out my “Projects” page which can be accessed via the icon in the top right and has a link to the powerpoint I presented to the class. Also feel free to reach out to me if you have any questions!